# 1. 前言
在关于 React 的面试中,有一道非常著名的面试题,那就是:
setState 到底是同步的,还是异步的?
针对这个问题,稍微有一点 React 开发经验的同学此时就会说出这样的回答: setState 在大多数情况下表现都是异步的,但是在 xxx 情况下表现是同步的。那么为什么会出现时而同步时而异步的这种现象呢?
接下来的文章就从源码角度来剖析一下 setState 背后的工作机制,探究一下它为什么会有上述所说的表现。
大多数人只要谈起 setState 的运行机制,那么肯定会辅以这样一段 Demo 加以说明,如下:
import React from "react";
export default class App extends React.Component {
state = {
count: 0
};
increment = () => {
console.log("increment setState前的count", this.state.count);
this.setState({
count: this.state.count + 1
});
console.log("increment setState后的count", this.state.count);
};
triple = () => {
console.log("triple setState前的count", this.state.count);
this.setState({
count: this.state.count + 1
});
this.setState({
count: this.state.count + 1
});
this.setState({
count: this.state.count + 1
});
console.log("triple setState后的count", this.state.count);
};
reduce = () => {
setTimeout(() => {
console.log("reduce setState前的count", this.state.count);
this.setState({
count: this.state.count - 1
});
console.log("reduce setState后的count", this.state.count);
}, 0);
};
render() {
return (
<div>
<button onClick={this.increment}>点我增加</button>
<button onClick={this.triple}>点我增加三倍</button>
<button onClick={this.reduce}>点我减少</button>
</div>
);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
此时浏览器里渲染出来的是如下图所示的三个按钮:
接下来,我们从左至右依次点击页面上的这三个按钮,来观察控制台上的输出情况。在点击之前,我们不妨先停下来猜猜控制台上会输出什么样的结果,看看你的猜测是否与最终控制台真实输出的结果相同。
控制台真实输出如下:
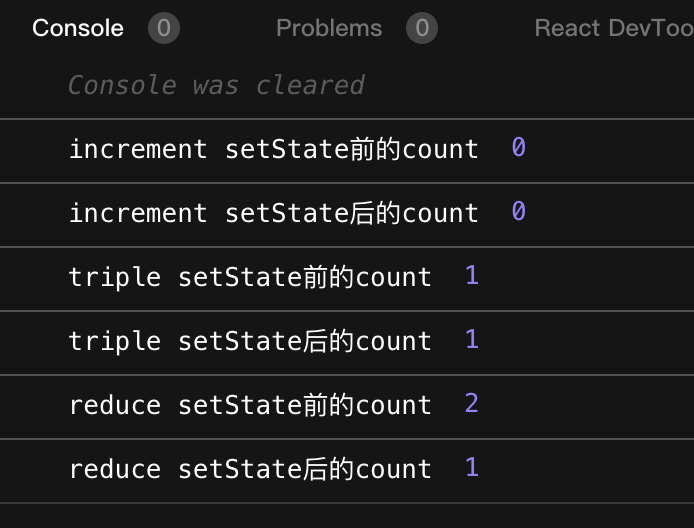
如果你的猜测与控制台真实输出的结果一样,那么恭喜你,你对 setState 的工作机制了解的很正确。如果你的猜测与控制台输出不一样,那也不要着急,接下来,本文就将从源码的角度来剖析 setState 的底层工作机制,探究一下为什么会出现这样的输出结果。
# 2. 引出批量更新
在探究 setState 的工作机制之前,我们先来看看当我们调用 setState 之后都发生了哪些事?
从页面的点击效果来看,当调用 setState 之后,此时组件会更新,如果你熟悉 React 的生命周期的话,那么你肯定知道此时会走到组件更新生命周期流程中,其过程如下:
setState ---> shouldComponentUpdate ---> componentWillUpdate ---> render ---> componentDidUpdate
可以看到,一个完整的更新流程,涉及了包括 re-render (重渲染) 在内的多个步骤。 re-render 本身涉及对 DOM 的操作,它会带来较大的性能开销。假如每一次 setState 的调用都会触发一次 re-render ,那视图很可能没刷新几次就卡死了。
那让 setState 调用之后不要刷新视图可以吗?显然更不行, React 本身就倡导数据驱动视图,数据都变了视图却不刷新,这肯定是万万不行的。此时就陷入了一个矛盾之中,变也不行,不变也不行。那么该如何解决这个问题呢?或者说如何优化这个问题呢?
当然 React 肯定也看到了这一点,提出了对 setState 批量更新的策略,即:调用 setState 之后不要立即更新视图,而是把 setState 先「攒」起来,等时机成熟,再把 「攒」起来的 state 结果做合并,最后只针对最新的 state 值走一次更新流程。
其大致过程如下:
this.setState({
count: this.state.count + 1 ===> 入队,[count+1的任务]
});
this.setState({
count: this.state.count + 1 ===> 入队,[count+1的任务,count+1的任务]
});
this.setState({
count: this.state.count + 1 ===> 入队, [count+1的任务,count+1的任务, count+1的任务]
});
↓
合并 state,[count+1的任务]
↓
执行 count+1的任务
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
ok,有了 setState 会被批量更新的这个思想后,接下来我们就对照 React 源码,来看看 setState 是如何工作的。
# 3. setState 工作机制
首先,我们先来找到 setState 的入口函数,它在这里 (opens new window):
ReactComponent.prototype.setState = function(partialState, callback) {
this.updater.enqueueSetState(this, partialState);
if (callback) {
this.updater.enqueueCallback(this, callback, 'setState');
}
};
2
3
4
5
6
从入口函数中可以看到,入口函数根据传入参数的不同,将其分发到不同的功能函数中去。通常,我们调用 setState 更常见的方式是传入要修改的 state 对象,即以对象形式的入参,可以看到它直接调用了 this.updater.enqueueSetState 这个方法,它在这里 (opens new window):
enqueueSetState: function(publicInstance, partialState) {
// 根据 this 拿到当前的组件实例
var internalInstance = getInternalInstanceReadyForUpdate(publicInstance, 'setState');
// 为当前组件实例创建一个数组queue,用来存放将要更新的 state
var queue = internalInstance._pendingStateQueue || (internalInstance._pendingStateQueue = []);
// 将要更新的 state 存入到 queue中
queue.push(partialState);
// 调用 enqueueUpdate 来更新当前的组件实例
enqueueUpdate(internalInstance);
}
2
3
4
5
6
7
8
9
10
11
12
13
从上述代码中可以看到, enqueueSetState 其实就干了两件事:
- 把将要更新的
state用一个数组存起来,并且将这个数组挂到当前组件实例上; - 调用
enqueueUpdate来更新当前的组件实例;
我们继续追, enqueueUpdate 都干了些什么,它在这里 (opens new window):
function enqueueUpdate(component) {
ensureInjected();
// isBatchingUpdates标识着当前是否处于批量更新组件的阶段
if (!batchingStrategy.isBatchingUpdates) {
// 若当前没有处于批量更新组件的阶段,则立即更新组件
batchingStrategy.batchedUpdates(enqueueUpdate, component);
return;
}
// 否则,先把组件塞入 dirtyComponents 队列里,攒起来
dirtyComponents.push(component);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
上述代码中有一个 isBatchingUpdates 的变量,它是一个全局变量,用来标识当前是否处于批量更新组件的阶段,若当前没有处于批量更新组件的阶段,则立即更新组件,否则,先把组件塞入 dirtyComponents 队列里,攒起来。
isBatchingUpdates 就像是一把锁,它的初始值是 false ,意味着当前并未进行任何批量更新操作。每当 Reac t 调用 batchedUpdate 去执行更新动作时,会先把这个锁给「锁上」(置为 true ),表明现在正处于批量更新过程中。当锁被「锁上」的时候,任何需要更新的组件都只能暂时进入 dirtyComponents 里排队等候下一次的批量更新,而不能随意「插队」。
了解了「锁」这个概念后,我们继续往下看,如果当前没有处于批量更新组件的阶段,则立即更新组件,更新组件调用的是 batchingStrategy.batchedUpdates ,它在这里 (opens new window):
var ReactDefaultBatchingStrategy = {
// 全局唯一的锁标识
isBatchingUpdates: false,
// 发起更新动作的方法
batchedUpdates: function(callback, a, b, c, d, e) {
// 缓存锁变量
var alreadyBatchingStrategy = ReactDefaultBatchingStrategy.isBatchingUpdates
// 把锁“锁上”
ReactDefaultBatchingStrategy.isBatchingUpdates = true
if (alreadyBatchingStrategy) {
callback(a, b, c, d, e)
} else {
// 启动事务,将 callback 放进事务里执行
transaction.perform(callback, null, a, b, c, d, e)
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
从 batchedUpdates 定义中可以看到,在更新操作执行前,先将 isBatchingUpdates 置为 true ,即将锁先锁上,然后启动一个 React 事务来执行 callback 。
关于什么是 React 的 Transaction(事务) 机制,可查看这篇文章:理解React中的事务机制
在 transaction.perform(callback, null, a, b, c, d, e) 中的事务 wrapper 有两个,分别是:
var RESET_BATCHED_UPDATES = {
initialize: emptyFunction,
close: function() {
ReactDefaultBatchingStrategy.isBatchingUpdates = false;
}
};
var FLUSH_BATCHED_UPDATES = {
initialize: emptyFunction,
close: ReactUpdates.flushBatchedUpdates.bind(ReactUpdates)
};
var TRANSACTION_WRAPPERS = [FLUSH_BATCHED_UPDATES, RESET_BATCHED_UPDATES];
2
3
4
5
6
7
8
9
10
11
12
13
我们把这两个 wrapper 套进 Transaction 的执行机制里,不难得出一个这样的流程:

ok,到这里, setState 的工作机制就已经梳理完了。简单总结一下就是:当调用 setState 的时候,此时会将要更新的 state 存到一个数组 queue 里并挂载到当前组件实例上,然后进入 enqueueUpdate 准备更新组件,在更新组件之前,会先看下当前有没有正在更新的组件,即更新锁是否被锁上了,如果被锁上了,则将组件存入 dirtyComponents 数组中先「攒」起来,当正在更新的组件更新完毕后,此时锁会被打开,然后进行下一轮的更新。
在这里,你应该会有一个疑问:看上述分析的源码中, isBatchingUpdates 默认为 false ,也就是说在初始状态下锁是被打开的,那为什么在 Demo 示例中的组件还是被批量更新了呢?
其实不然,如果我们在 React 源码中全局搜索 batchedUpdates ,会发现调用它的地方很多,但与更新流有关的只有这两个地方:
- 生命周期中钩子函数中;
- 合成事件中;
想想看,我们能够调用 setState 的地方也就生命周期中钩子函数中和合成事件中。
在这两个地方, React 会将锁悄悄锁上,这是因为:
开发者很有可能在声明周期函数中调用 setState 。因此,需要通过开启 isBatchingUpdates 来确保所有的更新都能够进入 dirtyComponents 里去,进而确保初始渲染流程中所有的 setState 都是生效的。
在合成事件中也有可能会触发 setState 。为了确保每一次 setState 都有效, React 同样会在此开启 isBatchingUpdates 。
# 4. 回看 Demo
了解了 setState 的工作机制后,接下来我们站在底层角度再来回头看看文章一开始提到的那个 Demo 。
在上文 Demo 中,点击第一个按钮执行的是这个逻辑:
increment = () => {
console.log("increment setState前的count", this.state.count);
this.setState({
count: this.state.count + 1
});
console.log("increment setState后的count", this.state.count);
};
2
3
4
5
6
7
8
9
通过上文分析,我们得知,在 React 合成事件中, React 会将 isBatchingUpdates 置为 true ,也就是说此时点击按钮实际上执行的逻辑是这样的:
increment = () => {
// 进来先锁上
isBatchingUpdates = true
console.log('increment setState前的count', this.state.count)
this.setState({
count: this.state.count + 1
});
console.log('increment setState后的count', this.state.count)
// 执行完函数再放开
isBatchingUpdates = false
}
2
3
4
5
6
7
8
9
10
11
12
13
很明显,在未将 isBatchingUpdates 置为 false 之前, setState 触发的组件更新会被「攒」起来,也就说此时的 state 还未被更新,只有当事件的回调函数中的同步操作都执行完毕后,锁才会被打开,组件才会更新,从而使得 setState 看起来像是异步执行的。
同理,点击第二个按钮也是相同的逻辑,唯一有所区别的是: React 会把 「攒」起来的 state 结果做合并,最后只针对最新的 state 值走一次更新流程。
我们着重来看第三个按钮的逻辑,点击第三个按钮执行的逻辑实际上是这样的:
reduce = () => {
// 进来先锁上
isBatchingUpdates = true
setTimeout(() => {
console.log('reduce setState前的count', this.state.count)
this.setState({
count: this.state.count - 1
});
console.log('reduce setState后的count', this.state.count)
}, 0);
// 执行完函数再放开
isBatchingUpdates = false
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
可以看到,开头锁上的那个 isBatchingUpdates ,对 setTimeout 内部的执行逻辑完全没有约束力。因为 isBatchingUpdates 是在同步代码中变化的,而 setTimeout 的逻辑是异步执行的。当 setState 调用真正发生的时候, isBatchingUpdates 早已经被重置为了 false ,这就使得当前场景下的 setState 具备了立刻发起同步更新的能力。所以在特定的情境下, setState 会从 React 的批量更新管控中「逃脱」掉,使得它又看起来像是同步执行的。
# 5. 总结
setState 并不是单纯同步或异步的,它的表现会因调用场景的不同而不同:
在 React 钩子函数及合成事件中,它表现为异步;
而在 setTimeout 、 setInterval 等函数中,包括在 DOM 原生事件中,它都表现为同步。
这种差异,本质上是由 React 事务机制和批量更新机制的工作方式来决定的。